
우당탕탕 개발공부
파이썬 데이터 분석 - [ 데이터 프레임 ] 본문

데이터 프레임
데이터의 형태로, 행과 열로 구성된 사각형 모양의 표처럼 생겼다.
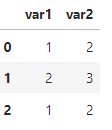
열 2, 행 3
2개의 속성에 대한 3개의 자료로 구성된 데이터 프레임
| '열'은 속성 | 컬럼 or 변수 |
| '행'은 정보 | 로우 or 케이스 |
| 데이터가 크다 ? ▶ 행이 많다 or 열이 많다 |
Q. 데이터 분석할 때 행이 많은 것과 열이 많은 것 중 어느 쪽이 더 중요하나요?
A. 열이 많은 것이 더 중요!
행이 늘어나더라도 분석 기술 면에서는 별 다른 차이가 생기지 않지만,
열이 늘어나는 경우에는 변수를 조합할 수 있는 경우의 수가 늘어나기 때문에 단순한 분석 방법으로는 해결하기 어렵기 때문이다.
행이 많다 → 컴퓨터 느려짐 → 고사양 장비 구축
열이 많다 → 분석 방법 한계 → 고급 분석 방법
1. 데이터 직접 입력하여 데이터 프레임 만들기
pandas 패키지 로드하기
ㄴ pandas는 데이터를 가공할 때 사용하는 패키지
import pandas as pd
데이터 프레임 만들기
pandas의 DataFrame( ) 사용하기
※ D, F 대문자로 입력하기 !!
df = pd.DataFrame( { 'name' : [ '전원우', '김민규', '부승관', '권순영' ],
'english' : [ 90, 80, 60, 70 ],
'math' : [50, 60, 100, 20]} )
df( 좋아하는 남자 아이돌 세븐틴의 멤버 이름을 사용해봤다..ㅎ..ㅎ 사심채우기 )
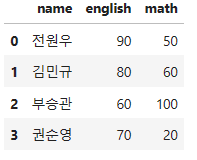
왼쪽에 표시된 숫자는 각 행이 몇 번째 순서에 위치하는 지 나타내는 인덱스(index) ,
인덱스(index)는 0부터 시작
데이터 분석하기
특정 변수 값 추출하기
프레임 이름 뒤에 [ ]를 입력한 다음 문자 형태로 변수명 입력하기
df['english']
변수의 값으로 합계 구하기
sum( ) 사용
sum(df['english'])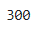
변수의 값으로 평균 구하기
sum(df['english']) / 4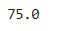
💛 혼자서 해보기 💛
Q1. 다음 표의 내용을 데이터 프레임으로 만들어 출력하기
A1.
fruit = pd.DataFrame( { '제품' : [ '사과', '딸기', '수박' ] ,
'가격' : [ 1800, 1500, 3000 ] ,
'판매량' : [24, 38, 13 ] } )
fruit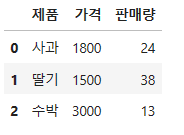
Q2. 과일의 가격 평균과 판매량 평균을 구하기
A2.
#가격 평균
sum(fruit['가격']) / 3
#판매량 평균
sum(fruit['판매량']) / 3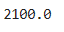
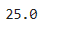
2. 외부 데이터 이용하기 - 엑셀
엑셀 파일 불러오기
.xlsx 파일 다운받기
워킹 디렉터리에 엑셀 파일 삽입
자신이 작업(사용)하고 있는 워킹 디렉토리에 불러 올 파일을 삽입
엑셀 파일 불러오기
pandas의 read_excel( ) 이용하여 파일 불러오기
파일명 앞뒤에 항상 따옴표(') 넣기 !!!
df_exam = pd.read_excel('excel_exam.xlsx')
df_exam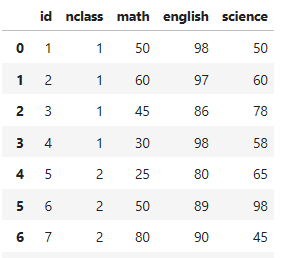
워킹 디렉터리가 아닌 다른 폴더에 있는 엑셀 파일을 불러 올 때 슬래시(/) 사용
분석하기
sum(df_exam['english']) / 20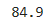
sum( ) + 학생 수 직접 입력을 하였는데
len( ) 함수를 사용하면 학생 수를 직접 입력하지 않아도 된다!
ㄴ len( )은 값의 개수를 구하는 함수
x= [1,2,3,4,5]
x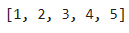
len(x)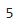
#데이터 프레임의 행 개수 구하기
df = pd.DataFrame( {'a' : [1,2,3],
'b' : [4,5,6]})
df
len( )이용해서 평균 점수 구해보기
len(df)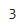
len(df_exam)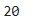
sum(df_exam['english']) / len(df_exam)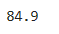
💥 엑셀 파일의 첫 번째 행이 변수명이 아닌 경우
read_excel( ) 에 header = None
None 입력시 'N'은 반드시 대문자 !!
💥 엑셀 파일에 시트가 여러개 있는 경우
read_excel( )에 sheet_name =
파이썬은 '0'부터 숫자를 세기 때문에 유의해서 표시하기
2. 외부 데이터 이용하기 - CSV
CSV 파일은 엑셀뿐 아니라 R, SAS, SPSS 등 데이터를 다루는 대부분의 프로그램에서 읽고 쓸 수 있는 범용 데이터 파일
확장자명에서 알 수 있듯이 CSV의 파일의 값들은 쉼표(,)로 구분된 형태
엑셀 파일보다 용량이 작고 다양한 프로그램에서 지원하기 때문에 자주 사용한다.
워킹 디렉터리에 CSV 파일 삽입하기
.csv 파일 다운 후 워킹 디렉터리에 삽입
CSV 파일 불러오기
pandas의 read_csv( ) 이용
df_csv_exam = pd.read_csv('exam.csv')
df_csv_exam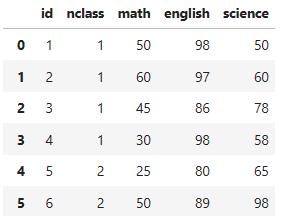
데이터 프레임을 CSV 파일로 저장하기
데이터 프레임 만들기
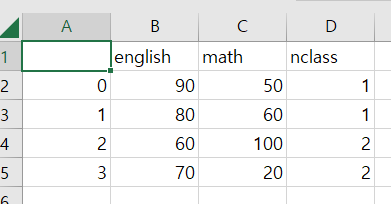
df_midterm = pd.DataFrame( { 'english' : [90,80,60,70],
'math' : [50,60,100,20],
'nclass' : [1,1,2,2]})
df_midterm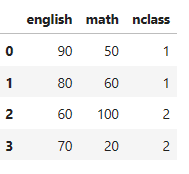
CSV 파일로 저장하기
데이터 프레임 이름 뒤에 점(.) 찍고 to_csv( ) , 괄호 안에 저장할 파일명 입력
df_midterm.to_csv("output_newdata.csv")
* 인덱스 번호 제외하고 저장 시
to_csv( ) 에 index = False 입력 , False의 'F'은 반드시 대문자!
df_midterm.to_csv("output_newdata.csv" index=False)

아직 재미있다 ㅎㅎ 예시로 연습하는 것도 좋지만 내가 원하는 변수명으로 하니까 더 이해가 잘 되는 거 같기도 ~ 데이터 프레임 만드는 방법, 외부 데이터 이용하는 방법 까먹지 말고 복습하자 !! 대문자 조심하기 👀
'✍ Study > 데이터 분석' 카테고리의 다른 글
| 파이썬 데이터 분석 - [ 데이터 분석 기초편2 ] (0) | 2023.01.04 |
|---|---|
| 파이썬 데이터 분석 - [ 데이터 분석 기초편 ] (0) | 2023.01.04 |
| 파이썬 데이터 분석 - [ 패키지 ] (0) | 2023.01.03 |
| 파이썬 데이터 분석 - [ 함수 ] (0) | 2023.01.02 |
| 파이썬 데이터 분석 - [ 변수 ] (0) | 2023.01.02 |



