

우당탕탕 개발공부
파이썬 데이터 분석 - 사용자 행동 로그 데이터_퍼널 분석 본문
1. 해당 csv 파일 불러오기
import pandas as pd
import plotly.express as px
data = pd.read_csv('불러 올 파일 주소')
data
2. 인덱스 중복 열 삭제
- 열을 삭제하므로 axis=1
data.drop('Unnamed: 0', axis=1, inplace=True)
3. 질문 만들기!
❓ DAU(일간 활성 사용자수) 추이는?
어느 요일에 가장 많이 방문하는가?
❓ 사이트 체류시간 평균은?
조회만 한 유저, 카트에 담은 유저, 구매까지 한 유저별로 체류시간이 어떻게 다른가?-
❓ 퍼널 분석
어느 단계에서 유저들이 가장 많이 이탈하는가?
4. 데이터 전처리
data.info()1️⃣ event-time이 문자형태로 되어 있기 때문에 데이터 타입을 변경
data['event_time'] = pd.to_datetime(data['event_time'], format='%Y-%m-%d %H:%M:%S UTC')
2️⃣ 결측치 제거
# 결측치 확인하기
data.isna().sum()이번 분석에서는 카테고리, 브랜드 분석이 아니므로 결측치를 제거해주기
3️⃣ 날짜 컬럼 추가
이미 datetiem으로 바꿔놨기 때문에 dt연산자를 활용해 컬럼을 추가
data['date_ymd'] = data['event_time'].dt.date
data.head()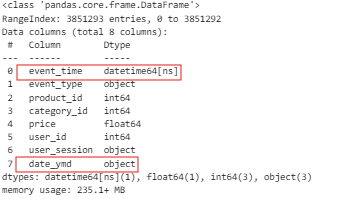
그런데! 문자로 추가가 되었다 ! 그렇기 때문에 다시한번 형변환을 해주기!
data['date_ymd'] = pd.to_datetime(data['date_ymd'], format='%Y-%m-%d')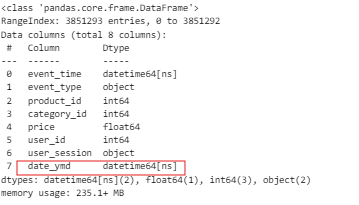
5. 데이터 분석
❓ DAU(일간 활성 사용자수) 추이는?
dau = data.groupby('date_ymd')[['user_id']].nunique().reset_index()
.rename({'user_id' : 'daut'}, axis=1)
dau
DAU추이 시각화
fig = px.line(data_frame = dau, x='date_ymd', y='dau', title='DAU 추이')
fig.show()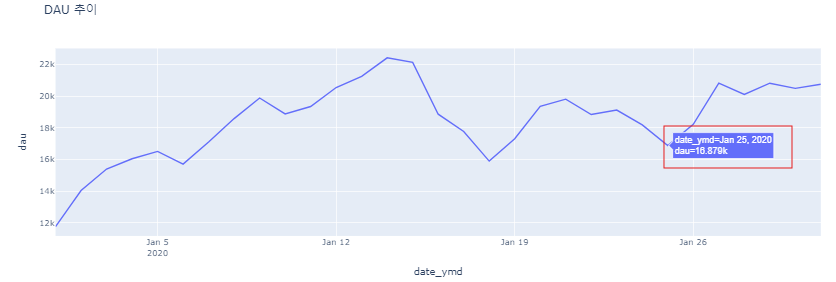
요일 별 가장 많이 방문한 요일
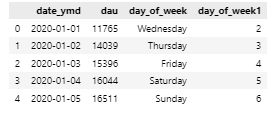
dau['day_of_week'] = dau['date_ymd'].dt.day_name()
dau['day_of_week1'] = dau['date_ymd'].dt.day_of_week
dau.head()day_name() : 요일을 영어로 표시
.day_of_week : 요일을 숫자로 표시
# 1. day_of_week1을 중심으로 평균 구하기
avg_dau_by_dow = dau.groupby(['day_of_week','day_of_week1'])[['dau']].mean().reset_index()
# 2. day_of_week1을 순서대로(월-일) 오름차순 정렬
avg_dau_by_dow.sort_values('day_of_week1', inplace=True)
avg_dau_by_dow
Bar 그래프로 확인해보기
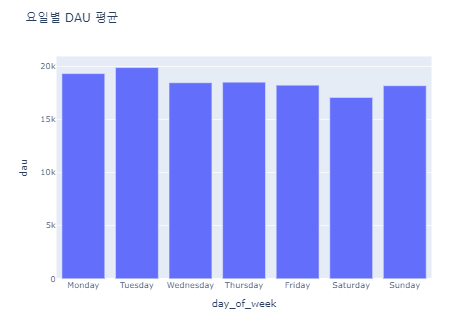
➡ 화요일이 가장 DAU평균이 높고 주말로 갈 수록 낮아지는 것을 확인할 수 있다!
❓ 사이트 체류시간 평균은?
한 user_session의 끝 event_time에서 시작 event_time을 뺀 값으로 체류시간을 구한다!
print(data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"')['event_time'].max()) #끝
print(data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"')['event_time'].min()) #시작
# 끝 시간- 시작 시간
print(data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"')['event_time'].max() - data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"')['event_time'].min())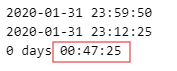
그렇다면! user_session 별로 구해보자
# 'user_session'을 그룹으로 묶고 'event_time'에 max와min 구하도록 함
duration = data.groupby('user_session')[['event_time']].agg(['max','min']).reset_index()
# max - min
duration['duration'] = duration['event_time']['max'] - duration['event_time']['min']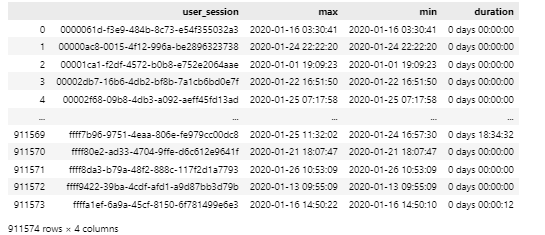
# 체류시간 평균 구하기
duration['duration'].mean()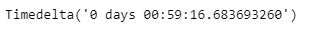
약 1시간 정도 머물고 있다는 것을 알 수 있다!
그렇다면, 조회만 한 유저, 카트에 담은 유저, 구매까지 한 유저별로 체류시간이 어떻게 다른가?
# Null 값은 0으로 바꾸기
session_pivot = pd.pivot_table(data=data, index='user_session', columns='event_type', values='event_time', aggfunc='count').reset_index().fillna(0)
session_pivot
# cart에 넣은 행동이 0보다 크다면 카트에 담은 행동이 있다는 것이고
cart_session = list(session_pivot.query('cart > 0')['user_session'])
# purchase이 0보다 크다면 구매를 했다는 것을 알 수 있음
purchase_session = list(session_pivot.query('purchase > 0')['user_session'])
user_session not in @cart_session and user_session not in @purchase_session
> 만약 user_session이 cart_session도 없고, purchase_session 없다면 .....
즉, 조회만 한 유저의 평균시간
# 조회만 한 유저의 평균 시간
duration.query('user_session not in @cart_session and user_session not in @purchase_session')['duration'].mean()
view_session_avg_duration = duration.query('user_session not in @cart_session and user_session not in @purchase_session')['duration'].mean()
cart_session_avg_duration = duration.query('user_session in @cart_session')['duration'].mean() #카트에 담은 유저 평균시간
purchase_session_avg_duration = duration.query('user_session in @purchase_session')['duration'].mean() #구매까지한 유저 평균시간
print(f'조회만 한 유저의 평균 체류시간: {view_session_avg_duration}')
print(f'카트에 담은 유저의 평균 체류시간: {cart_session_avg_duration}')
print(f'구매까지 한 유저의 평균 체류시간: {purchase_session_avg_duration}')
➡ 카트에서 구매까지 넘어간 유저의 평균 체류시간이 더 늘어난 것을 알 수 있다
❓ 퍼널 분석 : 어느 단계에서 유저들이 가장 많이 이탈하는가?
각 event_type별 몇 번 일어났는지 횟수 확인
session_pivot[['view','cart','remove_from_cart','purchase']].sum()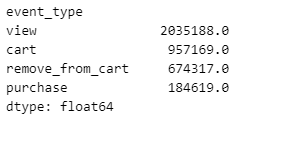
데이터 프레임으로 변환 후 컬럼 명 변경, 불필요한 컬럼 삭제를 해준
funnel = session_pivot[['view','cart','remove_from_cart','purchase']].sum().to_frame().reset_index()
funnel.columns = ['event_type','count']
funnel = funnel.query('event_type != "remove_from_cart"')
funnel
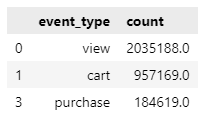
각 단계로 넘어가면서 이탈이 되었다는 것을 알 수 있다.
이 결과를 시각화를 통해서 확인해보자!
fig = px.funnel(data_frame=funnel, x='event_type', y='count')
fig.update_traces(texttemplate="%{value:,.0f}") # 숫자 형식 변환
fig.show()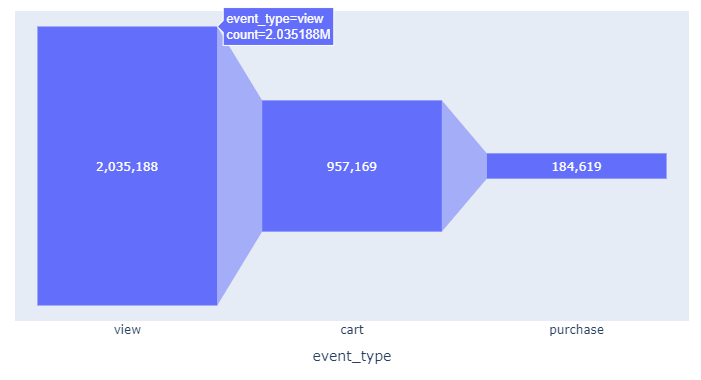
view에서 마지막 purchase까지 이탈 수가 많다는 것을 확인할 수 있음!
>> view에서 cart로 넘어간 전환율
view_to_cart_rate = list(funnel['count'])[1] / list(funnel['count'])[0]
>> view에서 purchase로 넘어간 전환율
view_to_purchase_rate = list(funnel['count'])[2] / list(funnel['count'])[0]
retain_rate 컬럼 추가 후 확인해보기
funnel['retain_rate'] = [1, view_to_cart_rate, view_to_purchase_rate]
funnel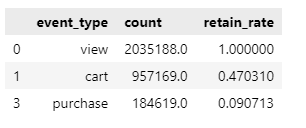
fig = px.funnel(data_frame=funnel, x='event_type', y='retain_rate')
fig.update_traces(texttemplate="%{value:,.2%}")
fig.show()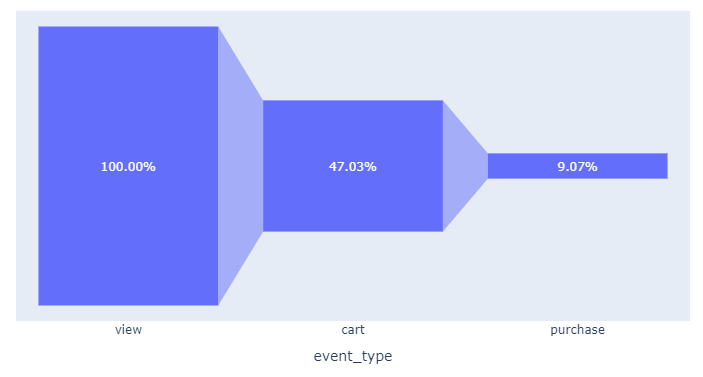
상품 조회가 100%라고 했을 때,
조회에서 장바구니 -> 47%
그 중 9%만 구매
➡ 조회에서 장바구니 이탈 비율보다 장바구니에서 구매 이탈 비율이 더 크다!!
따라서 ..... 해당 단계에서 전환율을 높이기 위한 전략이 필요함!
ㄴ> 🤔 결제하는 방법에 불편함이 있는지?
ㄴ> 🤔 회원가입에서 문제가 없는지?
'✍ Study > 데이터 분석' 카테고리의 다른 글
| 파이썬 데이터 분석 - 네이버 웹툰 데이터_크롤링 실습 (0) | 2025.03.17 |
|---|---|
| 크롤링(Crawling) 환경 만들기 (0) | 2025.03.17 |
| 파이썬 데이터 분석 - 서울시 롯데리아와 맥도날드 지점 분석하기 (0) | 2023.04.13 |
| 파이썬 데이터 분석 - matplotlib 사용해서 '산점도' 그리기 (0) | 2023.04.04 |
| 파이썬 데이터 분석 - melt( )함수 데이터 재구조화 (0) | 2023.03.31 |


